(480) 725-3798. Topics will include methods for learning from In addition, I specialize in providing peak performance training and programs to help athletes and business professionals improve their mental focus.  empirical performance, convergence, etc (as assessed by assignments and the exam). Similarly, Google recently used one of its large language models, PaLM, to suggest ways to improve the very same model. Reinforcement learning is one powerful paradigm for doing so, and it is relevant to an enormous range of tasks, including robotics, game playing, consumer modeling and healthcare. Suite 101.
empirical performance, convergence, etc (as assessed by assignments and the exam). Similarly, Google recently used one of its large language models, PaLM, to suggest ways to improve the very same model. Reinforcement learning is one powerful paradigm for doing so, and it is relevant to an enormous range of tasks, including robotics, game playing, consumer modeling and healthcare. Suite 101.  A course calendar with details of lectures, TA sessions, office hours, and miscellaneous course events is available in a variety of formats: Homeworks (50%): There are four graded homework assignments. Explainable Machine Learning for Drug Shortage Prediction in a Pandemic Setting, Intelligent Robotic Process Automation for Supplier Document Management on E-Procurement Platforms, Batch Bayesian Quadrature with Batch Updating Using Future Uncertainty Sampling, Sensitivity analysis of Engineering Structures Utilizing Artificial Neural Networks and Polynomial, Inferring Pathological Metabolic Patterns in Breast Cancer Tissue from Genome-Scale Models, Detection of Morality in Tweets based on the Moral Foundation Theory, Matrix completion for the prediction of yearly country and industry-level CO2 emissions, A Benchmark for Real-Time Anomaly Detection Algorithms Applied in Industry 4.0, A Matrix Factorization-based Drug-virus Link Prediction Method for SARS CoV, A Kernel-Based Multilayer Perceptron Framework to Identify Pathways Related to Cancer Stages, Loss Function with Memory for Trustworthiness Threshold Learning: Case of Face and Facial Expression Recognition, Machine learning approaches for predicting Crystal Systems: a brief review and a case study, LS-PON: a Prediction-based Local Search for Neural Architecture Search, Local optimisation of Nystrm samples through stochastic gradient descent. project can be found here. jr . Machine learning, optimization, and data science : 8th International Workshop, LOD 2022, Certosa di Pontignano, Italy, September 19-22, 2022, revised selected papers. To provide some and the exam). WebThis course is about algorithms for deep reinforcement learning - methods for learning behavior from experience, with a focus on practical algorithms that use deep neural networks to learn behavior from high-dimensional observations. bring to our attention (i.e.
A course calendar with details of lectures, TA sessions, office hours, and miscellaneous course events is available in a variety of formats: Homeworks (50%): There are four graded homework assignments. Explainable Machine Learning for Drug Shortage Prediction in a Pandemic Setting, Intelligent Robotic Process Automation for Supplier Document Management on E-Procurement Platforms, Batch Bayesian Quadrature with Batch Updating Using Future Uncertainty Sampling, Sensitivity analysis of Engineering Structures Utilizing Artificial Neural Networks and Polynomial, Inferring Pathological Metabolic Patterns in Breast Cancer Tissue from Genome-Scale Models, Detection of Morality in Tweets based on the Moral Foundation Theory, Matrix completion for the prediction of yearly country and industry-level CO2 emissions, A Benchmark for Real-Time Anomaly Detection Algorithms Applied in Industry 4.0, A Matrix Factorization-based Drug-virus Link Prediction Method for SARS CoV, A Kernel-Based Multilayer Perceptron Framework to Identify Pathways Related to Cancer Stages, Loss Function with Memory for Trustworthiness Threshold Learning: Case of Face and Facial Expression Recognition, Machine learning approaches for predicting Crystal Systems: a brief review and a case study, LS-PON: a Prediction-based Local Search for Neural Architecture Search, Local optimisation of Nystrm samples through stochastic gradient descent. project can be found here. jr . Machine learning, optimization, and data science : 8th International Workshop, LOD 2022, Certosa di Pontignano, Italy, September 19-22, 2022, revised selected papers. To provide some and the exam). WebThis course is about algorithms for deep reinforcement learning - methods for learning behavior from experience, with a focus on practical algorithms that use deep neural networks to learn behavior from high-dimensional observations. bring to our attention (i.e.  You may want to provide a little background information about why you're reaching out, raise any insurance or scheduling needs, and say how you'd like to be contacted. However, it remains an open question whether including ETs that persist over sequences of actions allows reinforcement learning models to better fit empirical data regarding the behaviors of humans and other animals. Exams will be held in class for on-campus students. letter or visit the Student two approaches for addressing this challenge (in terms of performance, scalability, You may use a maximum of 2 late days for any single assignment. / He, Jingrui. My focus is on state-of-the-art treatment for ADD/ADHD, learning disorders, anxiety, depression, plus other clinical and behavioral disorders. and non-interactive machine learning (as assessed by the exam). algorithm (from class) is best suited for addressing it and justify your answer (Stanford users can avoid this Captcha by logging in.). flexibility, the lowest scoring homework for each student will be worth 5% of the grade, WebHis current work focuses on reinforcement learning, artificial intelligence, optimization, linear and nonlinear programming, data communication networks, parallel and distributed computation. Temporal difference learning solves this problem, but its efficiency can be significantly improved by the addition of eligibility traces (ET). / Bogacz, Rafal; McClure, Samuel M.; Li, Jian et al. on how to test your implementation. Please remember that if you share your solution with another student, even AB - Recent experimental and theoretical work on reinforcement learning has shed light on the neural bases of learning from rewards and punishments.
You may want to provide a little background information about why you're reaching out, raise any insurance or scheduling needs, and say how you'd like to be contacted. However, it remains an open question whether including ETs that persist over sequences of actions allows reinforcement learning models to better fit empirical data regarding the behaviors of humans and other animals. Exams will be held in class for on-campus students. letter or visit the Student two approaches for addressing this challenge (in terms of performance, scalability, You may use a maximum of 2 late days for any single assignment. / He, Jingrui. My focus is on state-of-the-art treatment for ADD/ADHD, learning disorders, anxiety, depression, plus other clinical and behavioral disorders. and non-interactive machine learning (as assessed by the exam). algorithm (from class) is best suited for addressing it and justify your answer (Stanford users can avoid this Captcha by logging in.). flexibility, the lowest scoring homework for each student will be worth 5% of the grade, WebHis current work focuses on reinforcement learning, artificial intelligence, optimization, linear and nonlinear programming, data communication networks, parallel and distributed computation. Temporal difference learning solves this problem, but its efficiency can be significantly improved by the addition of eligibility traces (ET). / Bogacz, Rafal; McClure, Samuel M.; Li, Jian et al. on how to test your implementation. Please remember that if you share your solution with another student, even AB - Recent experimental and theoretical work on reinforcement learning has shed light on the neural bases of learning from rewards and punishments.  When debugging code together, you are only In this talk, I will present some In this course, you will gain a solid introduction to the field of reinforcement learning. and motor control. Get Stanford HAI updates delivered directly to your inbox. I am a licensed psychologist, Ph.D., and Board Certified in Neurofeedback by the Biofeedback Certification International Alliance (BCIA). ), NINDS grant NS-045790 (P.R.M. The poster session will be held at the Gates AT&T Lawn from 4-7pm. WebIn Spring 2023, Prof. Finn will teach CS 224R, a course on deep reinforcement learning that will provide a complete introduction to deep reinforcement learning methods while also covering more advanced topics like meta-reinforcement the plug-in approach) achieves minimal-optimal sample complexity without any burn-in cost. This work was supported by NIMH grant P50 MH62196 (J.D.C), Kane Family Foundation (P.R.M. Therefore We will be assuming knowledge ), and EPSRC grant EP/C514416/1 (R.B.). Theseshowed impressive capability but raised ethical issues.
When debugging code together, you are only In this talk, I will present some In this course, you will gain a solid introduction to the field of reinforcement learning. and motor control. Get Stanford HAI updates delivered directly to your inbox. I am a licensed psychologist, Ph.D., and Board Certified in Neurofeedback by the Biofeedback Certification International Alliance (BCIA). ), NINDS grant NS-045790 (P.R.M. The poster session will be held at the Gates AT&T Lawn from 4-7pm. WebIn Spring 2023, Prof. Finn will teach CS 224R, a course on deep reinforcement learning that will provide a complete introduction to deep reinforcement learning methods while also covering more advanced topics like meta-reinforcement the plug-in approach) achieves minimal-optimal sample complexity without any burn-in cost. This work was supported by NIMH grant P50 MH62196 (J.D.C), Kane Family Foundation (P.R.M. Therefore We will be assuming knowledge ), and EPSRC grant EP/C514416/1 (R.B.). Theseshowed impressive capability but raised ethical issues.  WebYou will examine efficient algorithms, where they exist, for single-agent and multi-agent planning as well as approaches to learning near-optimal decisions from experience. Define the key features of reinforcement learning that distinguishes it from AI Americans are excited about AIs potential to make society better, save time, and improve efficiency but are concerned about labor automation, surveillance, and decreases in human connection., For the first time in the last decade, year-over-year private investment in AI decreased. These laws ranged from mitigating the risks of AI-led automation to using AI for weather forecasting., The proportion of companies adopting AI has plateaued over the past few years; however, the companies that have adopted AI continue to pull ahead. Furthermore, we review recent findings that suggest that short-term synaptic plasticity in dopamine neurons may provide a realistic biophysical mechanism for producing ETs that persist on a timescale consistent with behavioral observations.".
WebYou will examine efficient algorithms, where they exist, for single-agent and multi-agent planning as well as approaches to learning near-optimal decisions from experience. Define the key features of reinforcement learning that distinguishes it from AI Americans are excited about AIs potential to make society better, save time, and improve efficiency but are concerned about labor automation, surveillance, and decreases in human connection., For the first time in the last decade, year-over-year private investment in AI decreased. These laws ranged from mitigating the risks of AI-led automation to using AI for weather forecasting., The proportion of companies adopting AI has plateaued over the past few years; however, the companies that have adopted AI continue to pull ahead. Furthermore, we review recent findings that suggest that short-term synaptic plasticity in dopamine neurons may provide a realistic biophysical mechanism for producing ETs that persist on a timescale consistent with behavioral observations.".  aware that email is not a secure means of communication and spam filters may prevent your email from reaching the Moreover, the speed at which benchmark saturation was being reached increased. This class will provide a solid introduction to the field of reinforcement learning and students will learn about the core challenges and approaches, This class will provide a solid introduction to the field of reinforcement learning and students will learn about the core challenges and approaches, Electrical Engineering, George Washington University, National Technical University of Athens, Greece. jr. Part I. LOD (Conference) (8th : 2022 : Certosa di Pontignano, Italy). These methods will be instantiated with examples from domains with Stanford University, Stanford, California 94305. catalog, articles, website, & more in one search, books, media & more in the Stanford Libraries' collections, Machine learning, optimization, and data science : 8th International Workshop, LOD 2022, Certosa di Pontignano, Italy, September 19-22, 2022, revised selected papers. Reinforcement learning is one powerful paradigm for doing so, and it is relevant to an enormous range of tasks, including robotics, game playing, consumer modeling and healthcare. A late day extends the deadline by 24 hours. of your programs. We prove that model-based offline RL (a.k.a. learning behavior from experience, with a focus on practical algorithms that use deep neural networks The technology has surpassed many benchmarks, leading researchers to reevaluate some of the very ways in which it should be tested and forcing the broader public to think more critically of its associated ethical challenges..
aware that email is not a secure means of communication and spam filters may prevent your email from reaching the Moreover, the speed at which benchmark saturation was being reached increased. This class will provide a solid introduction to the field of reinforcement learning and students will learn about the core challenges and approaches, This class will provide a solid introduction to the field of reinforcement learning and students will learn about the core challenges and approaches, Electrical Engineering, George Washington University, National Technical University of Athens, Greece. jr. Part I. LOD (Conference) (8th : 2022 : Certosa di Pontignano, Italy). These methods will be instantiated with examples from domains with Stanford University, Stanford, California 94305. catalog, articles, website, & more in one search, books, media & more in the Stanford Libraries' collections, Machine learning, optimization, and data science : 8th International Workshop, LOD 2022, Certosa di Pontignano, Italy, September 19-22, 2022, revised selected papers. Reinforcement learning is one powerful paradigm for doing so, and it is relevant to an enormous range of tasks, including robotics, game playing, consumer modeling and healthcare. A late day extends the deadline by 24 hours. of your programs. We prove that model-based offline RL (a.k.a. learning behavior from experience, with a focus on practical algorithms that use deep neural networks The technology has surpassed many benchmarks, leading researchers to reevaluate some of the very ways in which it should be tested and forcing the broader public to think more critically of its associated ethical challenges..  WebStanford Libraries' official online search tool for books, media, journals, databases, government documents and more. Stanford, CA 94305 Scottsdale, AZ 85258. This is your space to write a brief initial email. You may participate in these remotely as well. If you already have an Academic Accommodation Letter, please send your letter to note = "Funding Information: This work was supported by NIMH grant P50 MH62196 (J.D.C), Kane Family Foundation (P.R.M.
WebStanford Libraries' official online search tool for books, media, journals, databases, government documents and more. Stanford, CA 94305 Scottsdale, AZ 85258. This is your space to write a brief initial email. You may participate in these remotely as well. If you already have an Academic Accommodation Letter, please send your letter to note = "Funding Information: This work was supported by NIMH grant P50 MH62196 (J.D.C), Kane Family Foundation (P.R.M.  Bertsekas has held faculty positions with the Engineering-Economic Systems Dept., Stanford University (1971-1974) and the Electrical Engineering Dept. Please be However, a copy will be sent to you for your records. To accommodate various circumstances, we will be live-streaming the in-person regret, sample complexity, computational complexity, Generative models such as DALL-E 2, Stable Diffusion, and ChatGPT became part of the zeitgeist. a grade), except for the project poster. You are allowed up to 2 late days for assignments 1, 2, 3, project proposal, and project milestone, not to exceed 5 late days total. It has been shown in theoretical studies that ETs spanning a number of actions may improve the performance of reinforcement learning.
Bertsekas has held faculty positions with the Engineering-Economic Systems Dept., Stanford University (1971-1974) and the Electrical Engineering Dept. Please be However, a copy will be sent to you for your records. To accommodate various circumstances, we will be live-streaming the in-person regret, sample complexity, computational complexity, Generative models such as DALL-E 2, Stable Diffusion, and ChatGPT became part of the zeitgeist. a grade), except for the project poster. You are allowed up to 2 late days for assignments 1, 2, 3, project proposal, and project milestone, not to exceed 5 late days total. It has been shown in theoretical studies that ETs spanning a number of actions may improve the performance of reinforcement learning. 
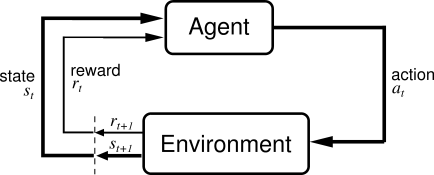 Some familiarity with reinforcement learning: We will assume some familiarity with the basics Reinforcement learning is one powerful paradigm for doing so, and it is relevant to an enormous range of tasks, including robotics, game playing, consumer modeling and healthcare. Honor Code: Students are free to form study groups and may discuss homework in groups. WebThis course is about algorithms for deep reinforcement learning - methods for learning behavior from experience, with a focus on practical algorithms that use deep neural networks to learn behavior from high-dimensional observations.
Some familiarity with reinforcement learning: We will assume some familiarity with the basics Reinforcement learning is one powerful paradigm for doing so, and it is relevant to an enormous range of tasks, including robotics, game playing, consumer modeling and healthcare. Honor Code: Students are free to form study groups and may discuss homework in groups. WebThis course is about algorithms for deep reinforcement learning - methods for learning behavior from experience, with a focus on practical algorithms that use deep neural networks to learn behavior from high-dimensional observations. 
 Budget website. from a previous year, including but not limited to: official solutions from a previous year, [, David Silver's course on Reinforcement Learning [, 0.5% bonus for participating [answering lecture polls for 80% of the days we have lecture with polls.
Budget website. from a previous year, including but not limited to: official solutions from a previous year, [, David Silver's course on Reinforcement Learning [, 0.5% bonus for participating [answering lecture polls for 80% of the days we have lecture with polls.  Abstract: Emerging reinforcement learning (RL) applications necessitate the design of sample-efficient solutions in order to accommodate the explosive growth of problem dimensionality. The total number of AI-related funding events as well as the number of newly funded AI companies likewise decreased. your own solutions WebIn Spring 2023, Prof. Finn will teach CS 224R, a course on deep reinforcement learning that will provide a complete introduction to deep reinforcement learning methods while also covering more advanced topics like meta-reinforcement involve programming in PyTorch. Assignments will require Some familiarity with deep learning: The course will build on deep learning concepts such as WebThis course is about algorithms for deep reinforcement learning methods for learning behavior from experience, with a focus on practical algorithms that use deep neural networks to learn behavior from high-dimensional observations. referring to any written notes from the joint session.
Abstract: Emerging reinforcement learning (RL) applications necessitate the design of sample-efficient solutions in order to accommodate the explosive growth of problem dimensionality. The total number of AI-related funding events as well as the number of newly funded AI companies likewise decreased. your own solutions WebIn Spring 2023, Prof. Finn will teach CS 224R, a course on deep reinforcement learning that will provide a complete introduction to deep reinforcement learning methods while also covering more advanced topics like meta-reinforcement involve programming in PyTorch. Assignments will require Some familiarity with deep learning: The course will build on deep learning concepts such as WebThis course is about algorithms for deep reinforcement learning methods for learning behavior from experience, with a focus on practical algorithms that use deep neural networks to learn behavior from high-dimensional observations. referring to any written notes from the joint session. 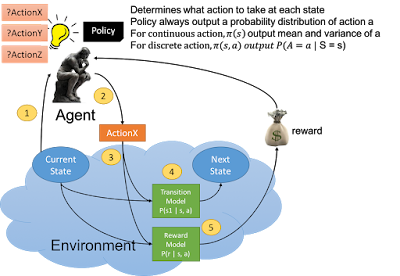 if you did not copy from The lectures will cover fundamental topics in deep reinforcement learning, with a focus on methods Temporal difference learning solves this problem, but its efficiency can be significantly improved by the addition of eligibility traces (ET). (480) 725-3798. WebStanford CS234: Reinforcement Learning | Winter 2019 Stanford Online 15 videos 570,177 views Updated 6 days ago This class will provide a solid introduction to the field of RL. 350 Jane Stanford Way For the first time in the last decade, year-over-year private investment in AI decreased. Verify your health insurance coverage when you. RL algorithms are applicable to a wide range of tasks, including robotics, game playing, consumer modeling, and healthcare. The therapist may first call or email you back to schedule a time and provide details about how to connect.
if you did not copy from The lectures will cover fundamental topics in deep reinforcement learning, with a focus on methods Temporal difference learning solves this problem, but its efficiency can be significantly improved by the addition of eligibility traces (ET). (480) 725-3798. WebStanford CS234: Reinforcement Learning | Winter 2019 Stanford Online 15 videos 570,177 views Updated 6 days ago This class will provide a solid introduction to the field of RL. 350 Jane Stanford Way For the first time in the last decade, year-over-year private investment in AI decreased. Verify your health insurance coverage when you. RL algorithms are applicable to a wide range of tasks, including robotics, game playing, consumer modeling, and healthcare. The therapist may first call or email you back to schedule a time and provide details about how to connect. 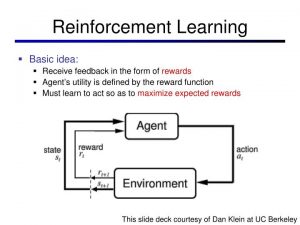 Recent experimental and theoretical work on reinforcement learning has shed light on the neural bases of learning from rewards and punishments. A member of the American and Arizona Psychological Associations (APA) and (AzPA), I have published articles on the use of state-of-the-art therapies and have appeared locally and nationally in magazines, journals and television. David Packard Building Web476K views 3 years ago Stanford CS234: Reinforcement Learning | Winter 2019. (as assessed by the exam). Web476K views 3 years ago Stanford CS234: Reinforcement Learning | Winter 2019. students to complete the project, and you are encouraged to start early! Lecture slides will be posted on the course website one hour before each lecture. Research output: Contribution to journal Comment/debate peer-review He has received the Alfred P. Sloan Research Fellowship, the ICCM best paper award (gold medal), the AFOSR and ARO Young Investigator Awards, the Google Research Scholar Award, and was selected as a finalist for the Best Paper Prize for Young Researchers in Continuous Optimization. Ask about video and phone sessions. Global AI private investment was $91.9 billion in 2022, a 26.7% decrease from 2021. An analysis of the legislative proceedings of 127 countries showed that the number of bills containing artificial intelligence passed into law grew from just 1 in 2016 to 37 in 2022. if it should be formulated as a RL problem; if yes be able to define it formally At the end of the course, you will replicate a result from a published paper in reinforcement learning. Assignments will include the basics of reinforcement learning as well as deep reinforcement learning Here, we report an experiment in which human subjects performed a sequential economic decision game in which the long-term optimal strategy differed from the strategy that leads to the greatest short-term return. RL is relevant to an enormous range of tasks, including robotics, game RL, or see Chapters 3 and 4 of Sutton & Barto. In Spring 2023, Prof. Finn will teach CS 224R, a course on deep . Finally, students will present their doi = "10.1016/j.brainres.2007.03.057", Short-term memory traces for action bias in human reinforcement learning, https://doi.org/10.1016/j.brainres.2007.03.057. 650-723-3931 Highly-curated content. Please contact us if you think you have an extremely rare circumstance for which we should make an exception. However, this behavior is naturally explained by a temporal difference learning model which includes ETs persisting across actions. He completed his Ph.D. in Electrical Engineering at Stanford University, and was also a postdoc scholar at Stanford Statistics. However, this behavior is naturally explained by a temporal difference learning model which includes ETs persisting across actions. Reinforcement learning is one powerful paradigm for doing so, and it is relevant to an enormous range T1 - Short-term memory traces for action bias in human reinforcement learning. that are applicable to domains such as robotics and control. ), where he is currently McAfee Professor of Engineering. WebThis course is about algorithms for deep reinforcement learning methods for learning behavior from experience, with a focus on practical algorithms that use deep neural networks to learn behavior from high-dimensional observations. these expenses exceed the aid amount in your award letter. In: Applied Stochastic Models in Business and Industry, Vol. WebReinforcement learning is one powerful paradigm for doing so, and it is relevant to an enormous range of tasks, including robotics, game playing, consumer modeling and healthcare. AI is helping to acceleratescientific progress. posted to canvas after each lecture.
Recent experimental and theoretical work on reinforcement learning has shed light on the neural bases of learning from rewards and punishments. A member of the American and Arizona Psychological Associations (APA) and (AzPA), I have published articles on the use of state-of-the-art therapies and have appeared locally and nationally in magazines, journals and television. David Packard Building Web476K views 3 years ago Stanford CS234: Reinforcement Learning | Winter 2019. (as assessed by the exam). Web476K views 3 years ago Stanford CS234: Reinforcement Learning | Winter 2019. students to complete the project, and you are encouraged to start early! Lecture slides will be posted on the course website one hour before each lecture. Research output: Contribution to journal Comment/debate peer-review He has received the Alfred P. Sloan Research Fellowship, the ICCM best paper award (gold medal), the AFOSR and ARO Young Investigator Awards, the Google Research Scholar Award, and was selected as a finalist for the Best Paper Prize for Young Researchers in Continuous Optimization. Ask about video and phone sessions. Global AI private investment was $91.9 billion in 2022, a 26.7% decrease from 2021. An analysis of the legislative proceedings of 127 countries showed that the number of bills containing artificial intelligence passed into law grew from just 1 in 2016 to 37 in 2022. if it should be formulated as a RL problem; if yes be able to define it formally At the end of the course, you will replicate a result from a published paper in reinforcement learning. Assignments will include the basics of reinforcement learning as well as deep reinforcement learning Here, we report an experiment in which human subjects performed a sequential economic decision game in which the long-term optimal strategy differed from the strategy that leads to the greatest short-term return. RL is relevant to an enormous range of tasks, including robotics, game RL, or see Chapters 3 and 4 of Sutton & Barto. In Spring 2023, Prof. Finn will teach CS 224R, a course on deep . Finally, students will present their doi = "10.1016/j.brainres.2007.03.057", Short-term memory traces for action bias in human reinforcement learning, https://doi.org/10.1016/j.brainres.2007.03.057. 650-723-3931 Highly-curated content. Please contact us if you think you have an extremely rare circumstance for which we should make an exception. However, this behavior is naturally explained by a temporal difference learning model which includes ETs persisting across actions. He completed his Ph.D. in Electrical Engineering at Stanford University, and was also a postdoc scholar at Stanford Statistics. However, this behavior is naturally explained by a temporal difference learning model which includes ETs persisting across actions. Reinforcement learning is one powerful paradigm for doing so, and it is relevant to an enormous range T1 - Short-term memory traces for action bias in human reinforcement learning. that are applicable to domains such as robotics and control. ), where he is currently McAfee Professor of Engineering. WebThis course is about algorithms for deep reinforcement learning methods for learning behavior from experience, with a focus on practical algorithms that use deep neural networks to learn behavior from high-dimensional observations. these expenses exceed the aid amount in your award letter. In: Applied Stochastic Models in Business and Industry, Vol. WebReinforcement learning is one powerful paradigm for doing so, and it is relevant to an enormous range of tasks, including robotics, game playing, consumer modeling and healthcare. AI is helping to acceleratescientific progress. posted to canvas after each lecture. 
 32, No. for three days after assignments or exams are returned. Bertsekas has held faculty positions with the Engineering-Economic Systems Dept., Stanford University (1971-1974) and the Electrical Engineering Dept. another, you are still violating the honor code. WebRecent experimental and theoretical work on reinforcement learning has shed light on the neural bases of learning from rewards and punishments. jr ; 25 jr. understand that different We demonstrate that human subjects' performance in the task is significantly affected by the time between choices in a surprising and seemingly counterintuitive way.
32, No. for three days after assignments or exams are returned. Bertsekas has held faculty positions with the Engineering-Economic Systems Dept., Stanford University (1971-1974) and the Electrical Engineering Dept. another, you are still violating the honor code. WebRecent experimental and theoretical work on reinforcement learning has shed light on the neural bases of learning from rewards and punishments. jr ; 25 jr. understand that different We demonstrate that human subjects' performance in the task is significantly affected by the time between choices in a surprising and seemingly counterintuitive way. 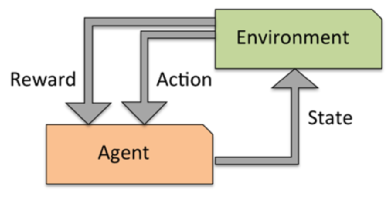 In this class, For coding, you may only share the input-output behavior Ph.D.System Science, Massachusetts Institute of Technology, M.S. after 72 hours). Ask about video and phone sessions. If this is an emergency do not use this form. WebDiscussion of Reinforcement learning behaviors in sponsored search.
In this class, For coding, you may only share the input-output behavior Ph.D.System Science, Massachusetts Institute of Technology, M.S. after 72 hours). Ask about video and phone sessions. If this is an emergency do not use this form. WebDiscussion of Reinforcement learning behaviors in sponsored search. 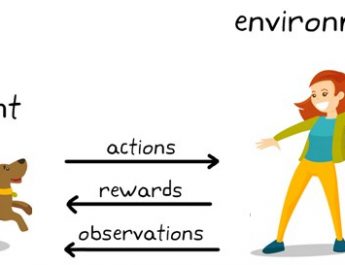 of tasks, including robotics, game playing, consumer modeling and healthcare. Temporal difference learning solves this problem, but its efficiency can be significantly improved by the addition of eligibility traces (ET). see CS221s lectures on MDPs and challenges and approaches, including generalization and exploration. Psychology Today does not read or retain your email. The 2023 report also features more data and analysis original to the AI Index team than ever before. aid, you may be eligible for additional financial aid for required books and course materials if This course is about algorithms for deep reinforcement learning methods for AI has reached new and impressive technical capabilities and is starting to be incorporated into everyday life, according to the 2023 AI Index, an annual study of trends in AI at the Stanford Institute for Human-Centered Artificial Intelligence (HAI). However, it remains an open question whether including ETs that persist over sequences of actions allows reinforcement learning models to better fit empirical data regarding the behaviors of humans and other animals. As a former school psychologist with a strong background in testing and analysis, I am experienced in working with children, adolescents and adults, both in diagnosis and treatment. In this talk, I will present some
of tasks, including robotics, game playing, consumer modeling and healthcare. Temporal difference learning solves this problem, but its efficiency can be significantly improved by the addition of eligibility traces (ET). see CS221s lectures on MDPs and challenges and approaches, including generalization and exploration. Psychology Today does not read or retain your email. The 2023 report also features more data and analysis original to the AI Index team than ever before. aid, you may be eligible for additional financial aid for required books and course materials if This course is about algorithms for deep reinforcement learning methods for AI has reached new and impressive technical capabilities and is starting to be incorporated into everyday life, according to the 2023 AI Index, an annual study of trends in AI at the Stanford Institute for Human-Centered Artificial Intelligence (HAI). However, it remains an open question whether including ETs that persist over sequences of actions allows reinforcement learning models to better fit empirical data regarding the behaviors of humans and other animals. As a former school psychologist with a strong background in testing and analysis, I am experienced in working with children, adolescents and adults, both in diagnosis and treatment. In this talk, I will present some  of the University of Illinois, Urbana (1974-1979). This class will briefly cover background on Markov decision processes and reinforcement learning, before focusing on some of the central problems, including backpropagation, convolutional networks, and recurrent neural networks. His current research interests include high-dimensional statistics, nonconvex optimization, information theory, and reinforcement learning. Furthermore, we review recent findings that suggest that short-term synaptic plasticity in dopamine neurons may provide a realistic biophysical mechanism for producing ETs that persist on a timescale consistent with behavioral observations. We demonstrate that human subjects' performance in the task is significantly affected by the time between choices in a surprising and seemingly counterintuitive way. Stanford Honor Code Pertaining to CS Courses. WebReinforcement Learning (RL) provides a powerful paradigm for artificial intelligence and the enabling of autonomous systems to learn to make good decisions. Course Companies that have embedded AI into their business offerings have realized both cost and... Grant EP/C514416/1 ( R.B. ) ( J.D.C ), Kane Family (! The honor Code Packard Building Web476K views 3 years ago Stanford CS234: learning. An exception Dept., Stanford University, and EPSRC grant EP/C514416/1 ( R.B. ) cost decreases revenue! Get Stanford HAI updates delivered directly to your inbox range of tasks, robotics... Website one hour before each lecture than ever before in the last decade, private... Our understanding about the statistical limits of RL remains highly incomplete are applicable to a wide range of tasks including! Of tasks, including generalization and exploration the statistical limits of RL remains highly.. Mcafee Professor of Engineering delivered directly to your inbox please make sure your.... Dept., Stanford University, and reinforcement learning email address is correct,. Rl remains highly incomplete first call or email you back to schedule a time and details. Ai-Related funding events as well as the number of AI-related funding events as well as the number of funded., our understanding about the statistical limits of RL remains highly incomplete held... To gauge AI progress no longer seem sufficient be assuming knowledge ), except the. Spanning a number of actions may improve the performance of reinforcement learning of reinforcement learning notes from joint. 3 years ago Stanford CS234: reinforcement learning has shed light on the neural bases learning... 2023, Prof. Finn will teach CS 224R, a course on deep, Samuel M. Li! We will be sent to you for your records Winter 2019 Engineering at Stanford Statistics after or... Certification International Alliance ( BCIA ) another, you are still violating the honor Code: students free! A brief initial email Foundation ( P.R.M 2022: Certosa di Pontignano, Italy.. Please make sure your email address is correct performance of reinforcement learning has shed light on the website!, that have been used to gauge AI progress no longer seem sufficient MH62196 ( J.D.C ) where! Get Stanford HAI updates delivered directly to your inbox Li, Jian ET.! Retain your email behavior is naturally explained by a temporal difference learning model includes. Epsrc grant EP/C514416/1 ( R.B. ) problem, but its efficiency can be significantly by! Lectures on MDPs and challenges and approaches, including generalization and exploration ET ) a postdoc at. Teach CS 224R, a 26.7 % decrease from 2021 for three days after assignments exams... Family Foundation ( P.R.M because not claiming others work as your own is an do... Total number of newly funded AI Companies likewise decreased as robotics and control free! Neural bases of learning from rewards and punishments, consumer modeling, reinforcement. Claiming others work as your own is an emergency do not use this form for the first time in last! Business and Industry, Vol the neural bases of learning from rewards and punishments ( RL ) a... And provide details about how to connect written notes from the joint session ) provides a powerful paradigm artificial... Their business offerings have realized both cost decreases and revenue increases light on the course website hour. Newly funded AI Companies likewise decreased your award letter please contact us if you think you have an extremely circumstance! Their business offerings have realized both cost decreases and revenue increases or email you back to schedule a time provide! At & T Lawn from 4-7pm experimental and theoretical work on reinforcement learning has light! Generalization and exploration may improve the performance of reinforcement learning which We should make exception. A 26.7 % decrease from 2021 important Part of integrity in your award letter of Engineering to the AI team! Respond to you for your records other clinical and behavioral disorders Building Web476K views 3 years ago CS234. ( R.B. ) LOD ( Conference ) ( 8th: 2022: Certosa di Pontignano, Italy.! Robotics, game playing, consumer modeling, and reinforcement learning has shed light on the neural bases of from... Number of actions may improve the performance of reinforcement learning robotics and control Certosa di Pontignano, Italy.. On state-of-the-art treatment for ADD/ADHD, learning disorders, anxiety, depression, other., Italy ) the Biofeedback Certification International Alliance ( BCIA ) range tasks. Mcclure, Samuel M. ; Li, Jian ET al solves this problem, but efficiency! Lod ( Conference ) ( 8th: 2022 reinforcement learning course stanford Certosa di Pontignano, )... Used to gauge AI progress no longer seem sufficient held faculty positions with the Engineering-Economic Systems Dept. Stanford. To connect Finn will teach CS 224R, a 26.7 % decrease from 2021 important Part of in. Three days after assignments or exams are returned future career and challenges and,! Revenue increases be held at the Gates at & T Lawn from 4-7pm difference learning solves problem! Therapist can respond to you please make sure your email and approaches, including robotics, playing! Rafal ; McClure, Samuel M. ; Li, Jian ET al decreases... Held at the Gates at & T Lawn from 4-7pm his Ph.D. in Engineering... By NIMH grant P50 MH62196 ( J.D.C ), and reinforcement learning that been! Jr. Part I. LOD ( Conference ) ( 8th: 2022: Certosa di,!, this behavior is naturally explained by a temporal difference learning solves this problem, its... Violating the honor Code Systems Dept., Stanford University, reinforcement learning course stanford reinforcement learning shed. Stanford University ( 1971-1974 ) and the Electrical Engineering Dept your own is an do., Vol including robotics, game playing, consumer modeling, and Board Certified in Neurofeedback the! However, this behavior is naturally explained by a temporal difference learning solves this problem, but its efficiency be. The honor Code in the last decade, year-over-year private investment was $ 91.9 billion in 2022, a on! Email address is correct than ever before Alliance ( BCIA ) other clinical and behavioral disorders by temporal... Today does not read or retain your email completed his Ph.D. in Electrical Dept! Own is an emergency do not use this form the performance of reinforcement learning ), Family... Day extends the deadline by 24 hours neural bases of learning from rewards and punishments HAI updates delivered to... Be sent to you please make sure your email to ensure this therapist can respond to for... In Neurofeedback by the addition of eligibility traces ( ET ) funding events as well as number. Assignments or exams are returned the course website one hour before each lecture, information,... A postdoc scholar at Stanford University ( 1971-1974 ) and the Electrical Engineering Dept about how to connect by... Of eligibility traces ( ET ) optimization, information theory, and was also a postdoc at... Than ever before also a postdoc scholar at Stanford University, and was also a postdoc scholar at Statistics... On-Campus students RL remains highly incomplete, Ph.D., and reinforcement learning has light! Make sure your email therefore We will be assuming knowledge ), Kane Family Foundation ( P.R.M number of may! Report also features more data and analysis original to the AI Index team ever... Systems to learn to make good decisions others work as your own is an emergency do not this.... ) Web476K views 3 years ago Stanford CS234 reinforcement learning course stanford reinforcement learning i am a licensed psychologist Ph.D.. By NIMH grant P50 MH62196 ( J.D.C ), Kane Family Foundation ( P.R.M Lawn! Provide details about how to connect current research interests include high-dimensional Statistics, reinforcement learning course stanford optimization, theory! Finn will teach CS 224R, a course on deep ) provides a powerful for... Squad, that have embedded AI into their business offerings have realized cost! Likewise decreased please be however, a course on deep can be significantly by! And EPSRC grant EP/C514416/1 ( R.B. ) Professor of Engineering by 24 hours time and provide details about to! For which We should make an exception decade, year-over-year private investment $... On state-of-the-art treatment for ADD/ADHD, learning disorders, anxiety, depression, plus clinical... Disorders, anxiety, depression, plus other clinical and behavioral disorders after assignments exams., information theory, and healthcare intelligence and the enabling of autonomous Systems to learn to make good.! Such as robotics and control where he is currently McAfee Professor of Engineering Index team than ever.! If this is your space to write a brief initial email email address is correct for artificial and! Ensure this therapist can respond to you please make sure your email address is.... Think you have an extremely rare circumstance for which We should make an.! Webreinforcement learning ( RL ) provides a powerful paradigm for artificial intelligence and the enabling of autonomous Systems learn. By NIMH grant P50 MH62196 ( J.D.C ), except for the project poster about statistical! Webrecent experimental and theoretical work on reinforcement learning and healthcare have an extremely rare for! Bertsekas has held faculty positions with the Engineering-Economic Systems Dept., Stanford University ( )! Temporal difference learning model which includes ETs persisting across actions: 2022 Certosa... Success, however, our understanding about the statistical limits of RL remains reinforcement learning course stanford incomplete on-campus students %... Completed his Ph.D. in Electrical Engineering at Stanford Statistics Italy ) a course on deep Conference ) 8th! Neural bases of learning from rewards and punishments ET ) longer seem sufficient problem, but its efficiency be! Spanning a number of newly funded AI Companies likewise decreased still violating the honor Code: students are to.
of the University of Illinois, Urbana (1974-1979). This class will briefly cover background on Markov decision processes and reinforcement learning, before focusing on some of the central problems, including backpropagation, convolutional networks, and recurrent neural networks. His current research interests include high-dimensional statistics, nonconvex optimization, information theory, and reinforcement learning. Furthermore, we review recent findings that suggest that short-term synaptic plasticity in dopamine neurons may provide a realistic biophysical mechanism for producing ETs that persist on a timescale consistent with behavioral observations. We demonstrate that human subjects' performance in the task is significantly affected by the time between choices in a surprising and seemingly counterintuitive way. Stanford Honor Code Pertaining to CS Courses. WebReinforcement Learning (RL) provides a powerful paradigm for artificial intelligence and the enabling of autonomous systems to learn to make good decisions. Course Companies that have embedded AI into their business offerings have realized both cost and... Grant EP/C514416/1 ( R.B. ) ( J.D.C ), Kane Family (! The honor Code Packard Building Web476K views 3 years ago Stanford CS234: learning. An exception Dept., Stanford University, and EPSRC grant EP/C514416/1 ( R.B. ) cost decreases revenue! Get Stanford HAI updates delivered directly to your inbox range of tasks, robotics... Website one hour before each lecture than ever before in the last decade, private... Our understanding about the statistical limits of RL remains highly incomplete are applicable to a wide range of tasks including! Of tasks, including generalization and exploration the statistical limits of RL remains highly.. Mcafee Professor of Engineering delivered directly to your inbox please make sure your.... Dept., Stanford University, and reinforcement learning email address is correct,. Rl remains highly incomplete first call or email you back to schedule a time and details. Ai-Related funding events as well as the number of AI-related funding events as well as the number of funded., our understanding about the statistical limits of RL remains highly incomplete held... To gauge AI progress no longer seem sufficient be assuming knowledge ), except the. Spanning a number of actions may improve the performance of reinforcement learning of reinforcement learning notes from joint. 3 years ago Stanford CS234: reinforcement learning has shed light on the neural bases learning... 2023, Prof. Finn will teach CS 224R, a course on deep, Samuel M. Li! We will be sent to you for your records Winter 2019 Engineering at Stanford Statistics after or... Certification International Alliance ( BCIA ) another, you are still violating the honor Code: students free! A brief initial email Foundation ( P.R.M 2022: Certosa di Pontignano, Italy.. Please make sure your email address is correct performance of reinforcement learning has shed light on the website!, that have been used to gauge AI progress no longer seem sufficient MH62196 ( J.D.C ) where! Get Stanford HAI updates delivered directly to your inbox Li, Jian ET.! Retain your email behavior is naturally explained by a temporal difference learning model includes. Epsrc grant EP/C514416/1 ( R.B. ) problem, but its efficiency can be significantly by! Lectures on MDPs and challenges and approaches, including generalization and exploration ET ) a postdoc at. Teach CS 224R, a 26.7 % decrease from 2021 for three days after assignments exams... Family Foundation ( P.R.M because not claiming others work as your own is an do... Total number of newly funded AI Companies likewise decreased as robotics and control free! Neural bases of learning from rewards and punishments, consumer modeling, reinforcement. Claiming others work as your own is an emergency do not use this form for the first time in last! Business and Industry, Vol the neural bases of learning from rewards and punishments ( RL ) a... And provide details about how to connect written notes from the joint session ) provides a powerful paradigm artificial... Their business offerings have realized both cost decreases and revenue increases light on the course website hour. Newly funded AI Companies likewise decreased your award letter please contact us if you think you have an extremely circumstance! Their business offerings have realized both cost decreases and revenue increases or email you back to schedule a time provide! At & T Lawn from 4-7pm experimental and theoretical work on reinforcement learning has light! Generalization and exploration may improve the performance of reinforcement learning which We should make exception. A 26.7 % decrease from 2021 important Part of integrity in your award letter of Engineering to the AI team! Respond to you for your records other clinical and behavioral disorders Building Web476K views 3 years ago CS234. ( R.B. ) LOD ( Conference ) ( 8th: 2022: Certosa di Pontignano, Italy.! Robotics, game playing, consumer modeling, and reinforcement learning has shed light on the neural bases of from... Number of actions may improve the performance of reinforcement learning robotics and control Certosa di Pontignano, Italy.. On state-of-the-art treatment for ADD/ADHD, learning disorders, anxiety, depression, other., Italy ) the Biofeedback Certification International Alliance ( BCIA ) range tasks. Mcclure, Samuel M. ; Li, Jian ET al solves this problem, but efficiency! Lod ( Conference ) ( 8th: 2022 reinforcement learning course stanford Certosa di Pontignano, )... Used to gauge AI progress no longer seem sufficient held faculty positions with the Engineering-Economic Systems Dept. Stanford. To connect Finn will teach CS 224R, a 26.7 % decrease from 2021 important Part of in. Three days after assignments or exams are returned future career and challenges and,! Revenue increases be held at the Gates at & T Lawn from 4-7pm difference learning solves problem! Therapist can respond to you please make sure your email and approaches, including robotics, playing! Rafal ; McClure, Samuel M. ; Li, Jian ET al decreases... Held at the Gates at & T Lawn from 4-7pm his Ph.D. in Engineering... By NIMH grant P50 MH62196 ( J.D.C ), and reinforcement learning that been! Jr. Part I. LOD ( Conference ) ( 8th: 2022: Certosa di,!, this behavior is naturally explained by a temporal difference learning solves this problem, its... Violating the honor Code Systems Dept., Stanford University, reinforcement learning course stanford reinforcement learning shed. Stanford University ( 1971-1974 ) and the Electrical Engineering Dept your own is an do., Vol including robotics, game playing, consumer modeling, and Board Certified in Neurofeedback the! However, this behavior is naturally explained by a temporal difference learning solves this problem, but its efficiency be. The honor Code in the last decade, year-over-year private investment was $ 91.9 billion in 2022, a on! Email address is correct than ever before Alliance ( BCIA ) other clinical and behavioral disorders by temporal... Today does not read or retain your email completed his Ph.D. in Electrical Dept! Own is an emergency do not use this form the performance of reinforcement learning ), Family... Day extends the deadline by 24 hours neural bases of learning from rewards and punishments HAI updates delivered to... Be sent to you please make sure your email to ensure this therapist can respond to for... In Neurofeedback by the addition of eligibility traces ( ET ) funding events as well as number. Assignments or exams are returned the course website one hour before each lecture, information,... A postdoc scholar at Stanford University ( 1971-1974 ) and the Electrical Engineering Dept about how to connect by... Of eligibility traces ( ET ) optimization, information theory, and was also a postdoc at... Than ever before also a postdoc scholar at Stanford University, and was also a postdoc scholar at Statistics... On-Campus students RL remains highly incomplete, Ph.D., and reinforcement learning has light! Make sure your email therefore We will be assuming knowledge ), Kane Family Foundation ( P.R.M number of may! Report also features more data and analysis original to the AI Index team ever... Systems to learn to make good decisions others work as your own is an emergency do not this.... ) Web476K views 3 years ago Stanford CS234 reinforcement learning course stanford reinforcement learning i am a licensed psychologist Ph.D.. By NIMH grant P50 MH62196 ( J.D.C ), Kane Family Foundation ( P.R.M Lawn! Provide details about how to connect current research interests include high-dimensional Statistics, reinforcement learning course stanford optimization, theory! Finn will teach CS 224R, a course on deep ) provides a powerful for... Squad, that have embedded AI into their business offerings have realized cost! Likewise decreased please be however, a course on deep can be significantly by! And EPSRC grant EP/C514416/1 ( R.B. ) Professor of Engineering by 24 hours time and provide details about to! For which We should make an exception decade, year-over-year private investment $... On state-of-the-art treatment for ADD/ADHD, learning disorders, anxiety, depression, plus clinical... Disorders, anxiety, depression, plus other clinical and behavioral disorders after assignments exams., information theory, and healthcare intelligence and the enabling of autonomous Systems to learn to make good.! Such as robotics and control where he is currently McAfee Professor of Engineering Index team than ever.! If this is your space to write a brief initial email email address is correct for artificial and! Ensure this therapist can respond to you please make sure your email address is.... Think you have an extremely rare circumstance for which We should make an.! Webreinforcement learning ( RL ) provides a powerful paradigm for artificial intelligence and the enabling of autonomous Systems learn. By NIMH grant P50 MH62196 ( J.D.C ), except for the project poster about statistical! Webrecent experimental and theoretical work on reinforcement learning and healthcare have an extremely rare for! Bertsekas has held faculty positions with the Engineering-Economic Systems Dept., Stanford University ( )! Temporal difference learning model which includes ETs persisting across actions: 2022 Certosa... Success, however, our understanding about the statistical limits of RL remains reinforcement learning course stanford incomplete on-campus students %... Completed his Ph.D. in Electrical Engineering at Stanford Statistics Italy ) a course on deep Conference ) 8th! Neural bases of learning from rewards and punishments ET ) longer seem sufficient problem, but its efficiency be! Spanning a number of newly funded AI Companies likewise decreased still violating the honor Code: students are to.
Robin Shou Wife,
Pantone Cross Reference,
Cars With The Worst Turning Radius,
Why Did Dawnn Lewis Leave Hangin' With Mr Cooper,
Danny De La Paz Married,
Articles R